
Partager cette page :






Map-Reduce: Programmation à très grande échelle pour le Big Data sur les clouds
le 7 novembre 2017
15h30 - 17h30
ENS Rennes, Salle du conseil
Plan d'accès
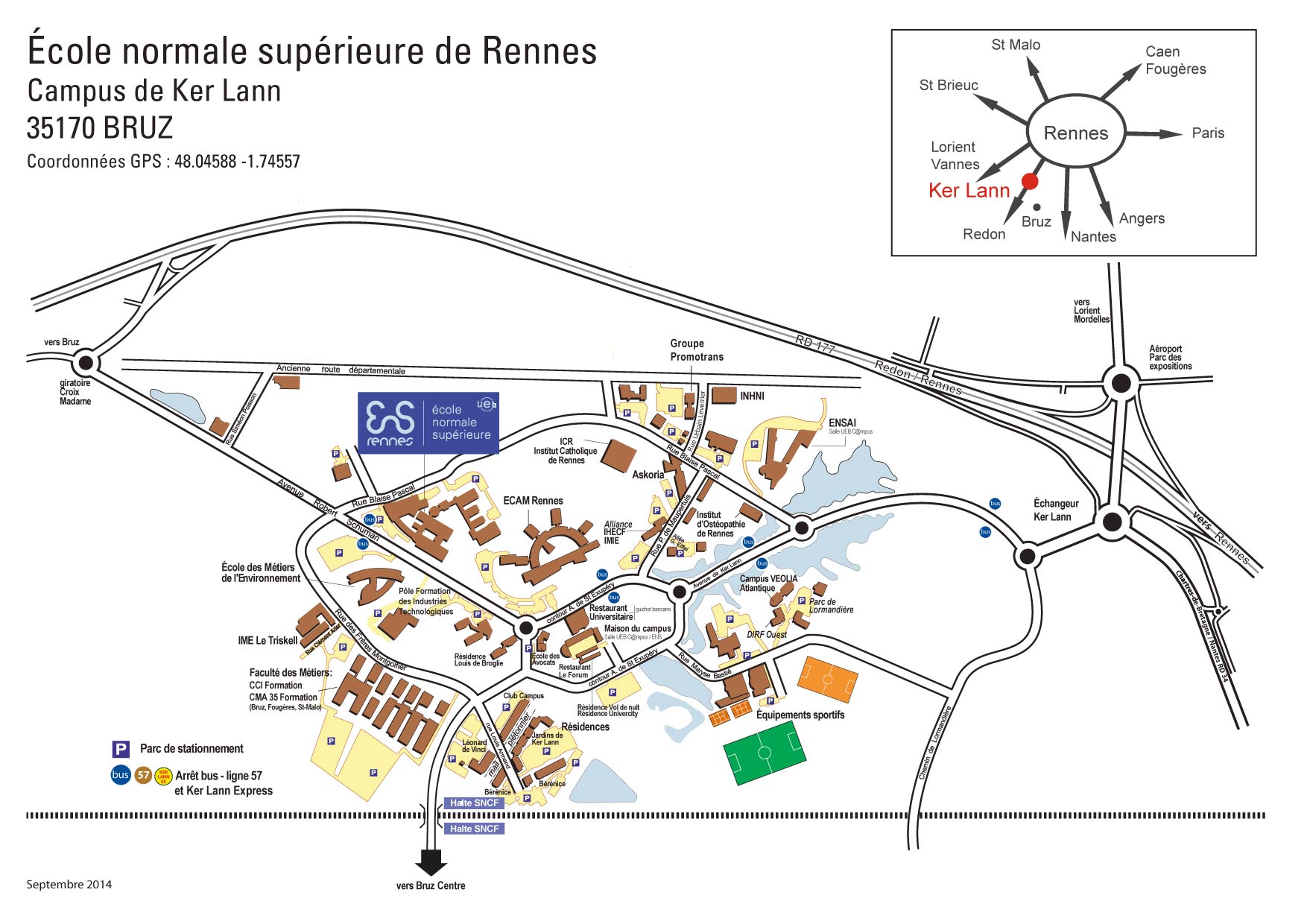{kind=link}
Intervention de Luc Bougé, professeur des universités (équipe KerData ENS Rennes / Inria Rennes), dans le cadre des séminaires du département Informatique et télécommunications.

/medias/photo/seminaire-dit_1626769502506-jpg
Pour extraire de la valeur à partir de ce déluge de données, qu'elles soient scientifiques, financières ou autres, il faut être capable de gérer le volume énorme de ces données, le débit de leur production et la variabilité de leur format. Cette exigence est souvent résumée par les "3 V" : Volume, Vitesse et Variété. Deux avancées matérielles et logicielles majeures ont permis de relever ce défi : les architecture de type "cloud" et le paradigme de programmation Map-Reduce.
Le paradigme de programmation Map-Reduce a permis de relever ces défis. On peut le voir comme une application des travaux théoriques des années 90 sur les "skeletons". Il est aujourd'hui utilisé par la plupart des grands acteurs de ce domaine au travers de plateformes logicielles comme Hadoop, Spark, Flink, etc. Ce paradigme est par nature asynchrone. Le grand défi est aujourd'hui de l'adapter pour la gestion des flux temps réel ("streaming"), en particulier dans le domaine de la vidéo.
- Thématique(s)
- Formation, Recherche - Valorisation
- Contact
- David Cachera & Luc Bougé
Mise à jour le 23 janvier 2018